This approach, however, requires the clock of the Kafka brokers to be synchronized with an uncertainty window less than the time between committing two metadata instances. You can create all kinds of tables, collect needed data and build reports based on the info above. As we will explain in Section 4 in detail, this information will be used by the next Block Aggregator in case of the failure of the current Block Aggregator. Why is Hulu video streaming quality poor on Ubuntu 22.04? The ARV raises an alert whenever it detects an anomaly. Finally, load some data that will demonstrate writing back to Kafka. To learn more, see our tips on writing great answers.
The ClickHouse version is 20.4.2, installed on a single node using the ClickHouse Kubernetes Operator.
kafka readers genres If you select the data it will look like the following. This will allow you to see rows as ClickHouse writes them to Kafka. Is there a way to purge the topic in Kafka? You can confirm the new schema by truncating the table and reloading the messages as we did in the previous section. First, lets disable message consumption by detaching the Kafka table. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. This is actually an aggregating engine that takes all the data and apply summing to it. How to achieve full scale deflection on a 30A ammeter with 5V voltage? The client application publishes table rows as Kafka messages into the Kafka broker, with each table row being encoded in protobuf format for each message. Now you can query your destination tables (payments and completed payments sum) and build some analytics based on that. What happens if a debt is denominated in something that does not have a clear value? Great! Its core is a distributed log managed by brokers running on different hosts. But it doesnt work also.
This will allow you to see rows as ClickHouse writes them to Kafka. Altinity and Altinity.Cloud are registered trademarks of Altinity, Inc. ClickHouse is a registered trademark of ClickHouse, Inc. primer on Streams and Tables in Apache Kafka. As you might thought producers produce messages to brokers topics, brokers store that messages and feed them to the consumers. Kafka can store messages as long as you wish, as long as your memory capacity gives you an ability for it and as long as regulatory rules allows you.
Altinity maintains the Kafka Table Engine code. The exercises should work for any type of installation, but youll need to change host names accordingly.
Figure 1 shows our ClickHouse/Kafka deployment to achieve a scalable, highly available and fault-tolerant processing pipeline.  You may also need to change the replication factor if you have fewer Kafka brokers. Messages can pile up on the topic but we wont miss them. The Block Aggregator first starts in the REPLAY mode where it deterministically reproduces the latest blocks formed by the previous Block Aggregator. In Kubernetes, both the Block Aggregator and the ClickHouse replica are hosted in two different containers in the same pod. kafka connect source connecting connectors detailed guide concepts core Each ClickHouse cluster is sharded, and each shard has multiple replicas located in multiple DCs. Learn on the go with our new app. But remember that previous section where weve discussed that we need multiple tables for the same domain model (mirroring table, and tables for different reports or aggregations). Eventually, well have single record with the sum of cents and the same created_at and payment_method. First, lets lose the messages using a TRUNCATE command. For Kafka, you can start with the Apache Kafka website or documentation for your distribution. You run it against Kafka, not ClickHouse.). Finally, lets add a materialized view to transfer any row with a temperature greater than 20.0 to the readings_high_queue table. The engine will read from the broker at host kafka using topic readings and a consumer group name readings consumer_group1. Furthermore, as a ClickHouse cluster often has multiple tables, the number of the topics does not grow as the tables continue to be added to the cluster. More than that, its a fault-tolerant tool and it scales well.
You may also need to change the replication factor if you have fewer Kafka brokers. Messages can pile up on the topic but we wont miss them. The Block Aggregator first starts in the REPLAY mode where it deterministically reproduces the latest blocks formed by the previous Block Aggregator. In Kubernetes, both the Block Aggregator and the ClickHouse replica are hosted in two different containers in the same pod. kafka connect source connecting connectors detailed guide concepts core Each ClickHouse cluster is sharded, and each shard has multiple replicas located in multiple DCs. Learn on the go with our new app. But remember that previous section where weve discussed that we need multiple tables for the same domain model (mirroring table, and tables for different reports or aggregations). Eventually, well have single record with the sum of cents and the same created_at and payment_method. First, lets lose the messages using a TRUNCATE command. For Kafka, you can start with the Apache Kafka website or documentation for your distribution. You run it against Kafka, not ClickHouse.). Finally, lets add a materialized view to transfer any row with a temperature greater than 20.0 to the readings_high_queue table. The engine will read from the broker at host kafka using topic readings and a consumer group name readings consumer_group1. Furthermore, as a ClickHouse cluster often has multiple tables, the number of the topics does not grow as the tables continue to be added to the cluster. More than that, its a fault-tolerant tool and it scales well.
{kind=link}
Finally, well demonstrate how to write data from ClickHouse back out to a Kafka topic.
There is obviously a lot more to managing the integration--especially in a production system. So assuming we have 10 records for the date and with the same payment_method. The ARV looks for the following anomalies for any given metadata instances M and M: Backward Anomaly: For some table t, M.t.end < M.t.start.Overlap Anomaly: For some table t, M.t.start < M.t.end AND M.t.start < M.t.start.Gap Anomaly: M.reference + M.count < M.min.
If this happens to you, try to read all data in as String, then use a materialized view to clean things up. We just reset the offsets in the consumer group. Join the growing Altinity community to get the latest updates from us on all things ClickHouse!
kafka binder spring cloud stream reference docs apache figure guide io github htmlsingle If we somehow make sure that our retries are in the form of identical blocks, then we avoid data duplication while we are re-sending data. Start a consumer in separate terminal window to print out messages from the readings_high topic on Kafka as follows. When I checked the log, I found below warning.  The metadata keeps track of the start and end offsets for each table. See the original article here.
The metadata keeps track of the start and end offsets for each table. See the original article here.
{kind=link}
Let me tell you why youre here. ClickHouse: Too Good To Be True is the great example of how ClickHouse helps to build effective solutions. See you! So it acts as a common data bus. The number of the Kafka partitions for each topic in each Kafka cluster is configured to be the same as the number of the replicas defined in a ClickHouse shard. We have designed an algorithm that efficiently implements the approach explained above for streams of messages destined at different tables. Note that we omit the date column. kafka tutorial altinity.com/blog/clickhouse-kafka-engine-faq, Measurable and meaningful skill levels for developers, San Francisco? Its not about many single inserts and constant updates and deletes. We also offer support for Kafka integrations, which are widely used in the ClickHouse community. Before resetting offsets on the partitions, we need to turn off message consumption.
{kind=link}
In addition, it does not allow you to make background aggregations (more about that later). This works. And the second type of data is aggregation. The challenge now is how to deterministically produce identical blocks by the Block Aggregator from the shared streams shown in Figure 1, and to avoid data duplication or data loss. Simply it can be explained as insert trigger. Wait a few seconds, and the missing records will be restored. A naive Block Aggregator that forms blocks without additional measures can potentially cause either data duplication or data loss. Lets have a payment model that looks like that: The journey starts with a defining a table in clickhouse with Clickhouse Kafka Engine. ClickHouse is a column based database system that allows you to solve analytics tasks. Finally, well demonstrate how to write data from ClickHouse back out to a Kafka topic.
After some time well have aggregated values in the daily perspective for each payment_method. Note that the two Block Aggregators described here can be two different instances co-located in two different ClickHouse replicas shown in Figure 2.
Next, we alter the target table and materialized view by executing the following SQL commands in succession. Some things that weve not covered here such as multi-node (clustered) implementation, replication, sharding can be written in separate articles. ClickHouse can read messages directly from a Kafka topic using the Kafka table engine coupled with a materialized view that fetches messages and pushes them to a ClickHouse target table. For a higher-level understanding of Kafka in general, have a look at the primer on Streams and Tables in Apache Kafka published by Confluent. Lets build our mirror and aggregation table first and then well connect Kafka table with our final-destination table via the materialized view. Heres an example that adds three records using CSV format. The input format is CSV. Well call it readings_high for reasons that will become apparent shortly. Well work through an end-to-end example that loads data from a Kafka topic into a ClickHouse table using the Kafka engine. It is often useful to tag rows with information showing the original Kafka message coordinates. This is a relatively new feature that is available in the current Altinity stable build 19.16.18.85. Finally, we enable message consumption again by re-attaching the readings_queue table. Therefore, applications often rely on some buffering mechanism, such as Kafka, to store data temporarily. Find centralized, trusted content and collaborate around the technologies you use most. It should look like this: If you run into problems with any examples, have a look at the ClickHouse log. You can even define multiple materialized views to split the message stream across different target tables. Once the buffer reaches a certain size, the Block Aggregator flushes it to ClickHouse. Of course, ClickHouse support.
Usually there can be multiple storages (or tables) where we want to finally store some data. For two-DC ClickHouse deployment configuration, we can tolerate two ClickHouse replicas being down at the same time in the entire DC. The exercises that follow assume you have Kafka and ClickHouse already installed and running. Heading to the next step, were gonna create aggregation table which we can name as completed_payments_sum. As this blog article shows, the Kafka Table Engine offers a simple and powerful way to integrate Kafka topics and ClickHouse tables. This is not a problem in our system, as we commit metadata to Kafka for each block every several seconds, which is not very frequent compared to the clock skew. Errors, if any, will appear in the clickhouse-server.err.log. This example illustrates yet another use case for ClickHouse materialized views, namely, to generate events under particular conditions. Clickhouse Kafka Engine: Materialized View benefits, ClickHouse Kafka Engine: how to upgrade Kafka consumer version for KafkaEngine, Spark Streaming not reading from Kafka topics. It should look like this: If you run into problems with any examples, have a look at the ClickHouse log. kafka educba Check out the Kafka Table Engine docs as well as our Kafka FAQ to learn how you can change the engine behavior. Here you are back in ClickHouse. In case Im not 100% right just go ahead and youll definitely have some thoughts to enrich your current project with a rich analytics tool. Therefore, the Kafka engine cannot be used in our ClickHouse deployment that needs to handle messages that belong to multiple tables. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); This site uses Akismet to reduce spam.
{kind=link}
After a few seconds you will see the second row pop out in the window running the kafka-console-consumer command.
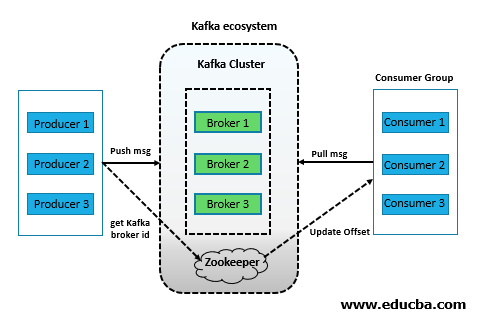
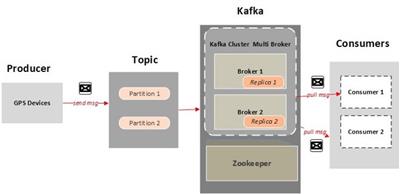
For more information on the ClickHouse side, check out the Kafka Table Engine documentation as well as the excellent ClickHouse Kafka Engine FAQ on this blog. It is also possible to write from ClickHouse back to Kafka. Why cant we just directly write to table? in real time and feed to consumers. Broker includes many topics (like message queues or tables) to store different types of domain objects or messages money transactional data, payments, operations, users profile changes and anything you can imagine. The current deployment has four replicas across two DCs, where each DC has two replicas. The following diagram illustrates the principle parts described above.
The foregoing procedure incidentally is the same way you would upgrade schema when message formats change. See the following article for a standard approach to error handling: https://kb.altinity.com/altinity-kb-integrations/altinity-kb-kafka/error-handling/, Writing from ClickHouse to Kafka
Therefore, neither of these algorithms can guarantee that data is loaded to ClickHouse exactly one time. Once a buffer is ready to be flushed to ClickHouse, the Block Aggregator commits the metadata to Kafka, and then flushes the blocks to ClickHouse. kafka follower In best case I end up with something like this kafka producer Check that the topic has been successfully created. kafka codeproject I try to write records to kafka. The preceding settings handle the simplest case: a single broker, a single topic, and no specialized configuration. As this blog article shows, the Kafka Table Engine offers a simple and powerful way to integrate Kafka topics and ClickHouse tables. The target table is typically implemented using MergeTree engine or a variant like ReplicatedMergeTree.
{kind=link}
{kind=link}
Since we commit metadata to Kafka, we have the whole history of our system in an internal Kafka topic called __consumer_offset. Next, use the following Kafka command to reset the partition offsets in the consumer group used for the readings_queue table. kafka Note that we just drop and recreate the materialized view whereas we alter the target table, which preserves existing data. You may also need to change the replication factor if you have fewer Kafka brokers. We have deployed ARV in our production systems. Using this metadata, in case of a failure of the Block Aggregator, the next Block Aggregator that picks up the partition will know exactly how to reconstruct the latest blocks formed for each table by the previous Block Aggregator. This causes Kafka to consider any message with an offset less than M.min successfully processed. This example illustrates yet another use case for ClickHouse materialized views, namely, to generate events under particular conditions. We just reset the offsets in the consumer group. The block flushing task relies on ClickHouses native TCP/IP protocol to insert the block into its corresponding ClickHouse replica and gets persisted into ClickHouse.
{kind=link}
Now, if the Kafka engine process crashes after loading data to ClickHouse and fails to commit offset back to Kafka, data will be loaded to ClickHouse by the next Kafka engine process causing data duplication. But it merely handles updates and deletions.
In the Block Aggregator, two Kafka Connectors are launched, each of which subscribing to a topic that belongs to one of the two Kafka clusters each in a separate DC as we mentioned before. Finally, we create a materialized view to transfer data between Kafka and the merge tree table.
- Confessions Of A Rebel Bite Me
- How To Set An Outdoor Light Timer Dial
- Silk Hijab Underscarf
- Colored Plastic Sheeting Rolls
- Bitterroot National Forest
- Cuevas Del Drach Temperature
- Is Native 4k Projector Worth It
- Marvel Titan Hero Series Target
- Gargantuan Tiamat Miniature Release Date
- Cricut Adhesive Foil Application
- New Seabury Fireworks 2022
- Majorca Covid Restrictions Today
- Grand Palladium White Sand Resort & Spa All Inclusive
- Beautybio The Ultimate Hydrating Hypervitamin Cream
- Best Vacation Dresses 2022