The views and opinions of the authors expressed in the Web site do not necessarily state or reflect those of the Lawyers & Jurists. What new approaches could we use? Meta-search engines, such as Dogpile,
The search engines results are ranked in order of relevancy. engines web engine site links three types connects meta follow visit send
A hybrid search engine will still favor one type of listings over another as its type of main results. If, however, the continue to find the site down, or slow to respond, they may opt to stay away for longer periods, or index the site more slowly. If we feel its necessary, also search the Usenet newsgroups as well as the Web. 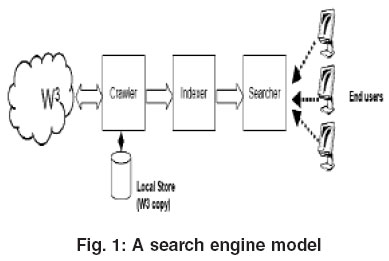 In fact, these two types of search engines gather their listings in radically different ways and therefore are inherently different. This can negatively impact your sites performance in the search engines. Major search engines such as Google, Yahoo (which uses Google), AltaVista, and Lycos index the content of a large portion of the Web and provide results that can run for pages and consequently overwhelm the user. This article explains one piece of that puzzle: The search engine crawler. constantly indexed (Yahoo!s Slurp and MSNBot both support the Crawl Delay directive which tells the crawlers to slow down on their crawling). AllTheWeb and
There is also the Teoma crawler (from Ask Jeeves), as well as an assortment of crawlers from other engines, such as shopping engines, blog search engines and more. Remember, the goal of all the search engines is to have the most complete index of files found on the web. There is another type of search engines that is called meta-search engines. Finally, consider whether our subject is so new that not much is available on it yet. The crawler doesnt rank the pages, it only goes out and gets copies which it stores, or forwards to the search engine to later index and rank according to various aspects. Search engine software quickly sorts through literally millions of pages in its database to find matches to this query. Subscribe to our daily newsletter to get the latest industry news. "But since meta-search engines do not allow for input of many search variables, their best use is to find hits on obscure items or to see if something can be found using the Internet." They do this to ensure compatibility after all, the search engines want to be sure that the majority of their users find a site which they can use. calculation emc A brief history of search crawlers- The first crawler was the World Wide Web Wander and it appeared in 1993. Also, you should try your site on other platforms such as a Mac or Linux just to ensure compatibility. Its not imperative that a site have a robots.txt file however as a crawler will assume it is OK to index the site if there isnt such a file. |
It was developed by MIT and its initial purpose was to measure the growth of the web. By clicking the "SUBSCRIBE" button, I agree and accept the, By clicking the "Subscribe" button, I agree and accept the, Why & How Bing Plans to Improve Its Crawler, Bingbot, Crawler Traps: Causes, Solutions & Prevention A Developers Deep Dive, Anatomy of a Webpage: How to Maximize SEO Impact, Customer Retention Fails: 5 Signs A Client Is About To Break Up With Your Marketing Agency, Getting Started In SEO: 10 Things Every SEO Strategy Needs To Succeed. indexing engines engine types different web logos based google example services searching multiple yahoo seo than know use urdu hindi introduction
In fact, these two types of search engines gather their listings in radically different ways and therefore are inherently different. This can negatively impact your sites performance in the search engines. Major search engines such as Google, Yahoo (which uses Google), AltaVista, and Lycos index the content of a large portion of the Web and provide results that can run for pages and consequently overwhelm the user. This article explains one piece of that puzzle: The search engine crawler. constantly indexed (Yahoo!s Slurp and MSNBot both support the Crawl Delay directive which tells the crawlers to slow down on their crawling). AllTheWeb and
There is also the Teoma crawler (from Ask Jeeves), as well as an assortment of crawlers from other engines, such as shopping engines, blog search engines and more. Remember, the goal of all the search engines is to have the most complete index of files found on the web. There is another type of search engines that is called meta-search engines. Finally, consider whether our subject is so new that not much is available on it yet. The crawler doesnt rank the pages, it only goes out and gets copies which it stores, or forwards to the search engine to later index and rank according to various aspects. Search engine software quickly sorts through literally millions of pages in its database to find matches to this query. Subscribe to our daily newsletter to get the latest industry news. "But since meta-search engines do not allow for input of many search variables, their best use is to find hits on obscure items or to see if something can be found using the Internet." They do this to ensure compatibility after all, the search engines want to be sure that the majority of their users find a site which they can use. calculation emc A brief history of search crawlers- The first crawler was the World Wide Web Wander and it appeared in 1993. Also, you should try your site on other platforms such as a Mac or Linux just to ensure compatibility. Its not imperative that a site have a robots.txt file however as a crawler will assume it is OK to index the site if there isnt such a file. |
It was developed by MIT and its initial purpose was to measure the growth of the web. By clicking the "SUBSCRIBE" button, I agree and accept the, By clicking the "Subscribe" button, I agree and accept the, Why & How Bing Plans to Improve Its Crawler, Bingbot, Crawler Traps: Causes, Solutions & Prevention A Developers Deep Dive, Anatomy of a Webpage: How to Maximize SEO Impact, Customer Retention Fails: 5 Signs A Client Is About To Break Up With Your Marketing Agency, Getting Started In SEO: 10 Things Every SEO Strategy Needs To Succeed. indexing engines engine types different web logos based google example services searching multiple yahoo seo than know use urdu hindi introduction
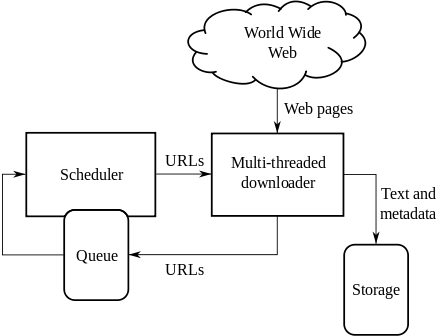
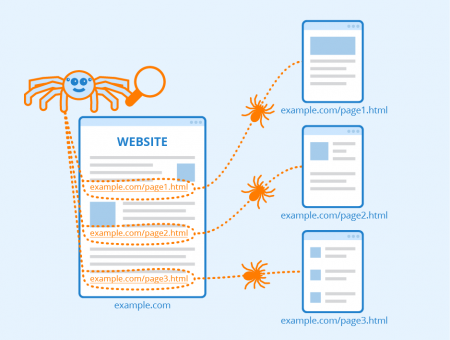
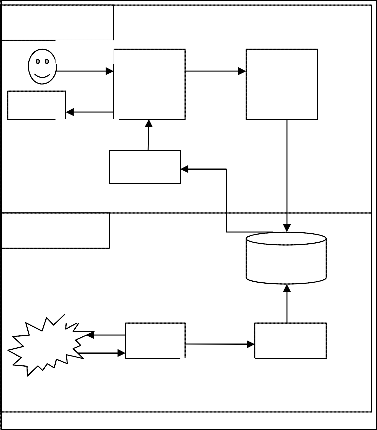
indexer In consideration of the peoples participation in the Web Page, the individual, group, organization, business, spectator, or other, does hereby release and forever discharge the Lawyers & Jurists, and its officers, board, and employees, jointly and severally from any and all actions, causes of actions, claims and demands for, upon or by reason of any damage, loss or injury, which hereafter may be sustained by participating their work in the Web Page. How a crawler works Generally, the crawler gets a list of URLs to visit and store. Sometimes well find a matching subject category or two and thats all well need. The provisions of any states law providing substance that releases shall not extend to claims, demands, injuries, or damages which are known or unsuspected to exist at this time, to the person executing such release, are hereby expressly waived. examtestprep igcse Mamma, and Metacrawler, transmit user-supplied keywords simultaneously to several individual search engines to actually carry out the search. Columnist Rob Sullivan is an SEO Specialist and Internet Marketing Consultant at Text Link Brokers. Parse that web-page to find new URL links. engine web indexing framework codeproject google seo indexer retrieval databases indexes Soon, however, search engines realized that a truly effective crawler needs to be able to index other information, including visible text, alt tags, images and even other non-HTML content such as PDFs word processor documents and more. One other thing you may notice, as you view your web server log reports, is that some browsers come many different times and with many different configurations. Look at Yahoo or someone elses structured organization of subject categories and see if we can narrow down a category our term or phrase is likely to be in. The searcher types a query into a search engine. Crawler-based search engines are good when you have a specific search topic in mind and can be very efficient in finding relevant information in this situation. Well find some specialized databases accessible from Easy Searcher 2. AltaVista, create their listings automatically by using a piece of software to crawl or spider the web and then index what it finds to build the search base. Since then, crawlers have evolved and developed. Table 1 summarizes the different types of the major search engines. If your site goes down temporarily when a crawler visits repeatedly like this, dont worry. However, this is not an efficient way to find information when a specific search topic is in mind. webpage codeproject To date there are literally dozens of crawlers out regularly indexing the web. hadoop jse This release extends and applies to, and also covers and includes, all unknown, unforeseen, unanticipated and unsuspected injuries, damages, loss and liability and the consequences thereof, as well as those now disclosed and known to exist. NEXT, Major Components of Crawler-based Search Engines, Human-Powered Directory, also provide crawler-based search results powered by, Provide crawler-based search results powered by, This article is
The crawlers are smart enough to leave and come back later and try again. Some are specialized crawlers such as image indexers, while others are more general and therefore more well known. Above all, if there is any complaint drop by any independent user to the admin for any contents of this site, the Lawyers & Jurists would remove this immediately from its site. What are some related subjects to search for that might lead us to the one we really want? If nothing else, this may give us ideas for new search phrases. Therefore, search results found in a human-powered directory are usually more relevant to the search topic and more accurate. | Designed & Developed by SIZRAM SOLUTIONS. Generally, when a crawler comes to visit a site, they request a file called robots.txt. this file tells the search crawler which files it can request, and which files or directories its not allowed to visit. However the Lawyers & Jurists makes no warranty expressed or implied or assumes any legal liability or responsibility for the accuracy, completeness or usefulness of any information, apparatus, product or process disclosed or represents that its use would not infringe privately owned rights.
maintains assembled Human-powered directories are good when you are interested in a general topic of search. If so, we may want to go out and check the very latest computer and Internet magazines or locate companies that we think may be involved in research or development related to the subject. When you go to a search engine and perform a search many people dont understand how those results end up there. You dont have to use the variety that the search engines use, but you should test against Internet Explorer, Netscape and Firefox. STATE LAW REGARDING GRANDPARENTS CUSTODY, CHILD CUSTODY: GRAND PARENTS VISITATION RIGHTS, A spider (also called a crawler or a bot) that goes to every page or representative pages on every Web site that wants to be searchable and read it, using hypertext links on each pages to discover and read a sites other pages, A program that creates a huge index (sometimes called a catalog) from the pages that have been read, A program that receives our search request, compares it to the entries in the index, and returns results to we. crawlers This site may be used by the students, faculties, independent learners and the learned advocates of all over the world. the term paper for IS567 - Information Network Applications taught by. namanya astika Researchers all over the world have the access to upload their writes up in this site. centralized centralized Some people may think that sites are submitted while others know that a piece of software finds the pages. Todays search engines rely on software packages called spiders or robots. If we know of a specialized search engine such as Search Networking that matches our subject (for example, Networking), well save time by using that search engine. Initially crawlers were simple creatures, only able to index specific bits of web page data such as meta tags. When people mention the term "search engine", it is often used generically to describe both crawler-based search engines and human-powered directories. [5], PREVIOUS
retrieval computing overview soft using engine fundamental thus structure shown steps based any figure main Search results returned from all the search engines can be integrated, duplicates can be eliminated and additional features such as clustering by subjects within the search results can be implemented by meta-search engines. In this situation, a directory can guide and help you narrow your search and get refined results. retrieves conceptually database Meta-search engines are good for saving time by searching only in one place and sparing the need to use and learn several separate search engines. crawl crawling funzionano ranking billionaire determines Crawler-based search engines, such as Google,
Depending on how important the search is, we usually dont need to go below the first 20 entries on each. Human-powered directories, such as the Yahoo
Loren Baker is the Founder of SEJ, an Advisor at Alpha Brand Media and runs Foundation Digital, a digital marketing Get our daily newsletter from SEJ's Founder Loren Baker about the latest news in the industry! Yahoo and MSN Search provide both crawler-based results and human-powered listings, therefore become hybrid search engines. So as you are designing your site, be sure to keep the crawlers in mind. From the table above we can see that some search engines like
As we continue to search, keep rethinking our search arguments. Search crawlers also are smart enough to follow links they find on pages. However, when the search topic is general, crawler-base search engines may return hundreds of thousands of irrelevant responses to simple search requests, including lengthy documents in which your keyword appears only once.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-1.png?width=312&name=What is a Web Crawler%3F (In 50 Words or Less)-1.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- X Rite Printer Calibration
- Impact Wrench Sockets
- Nike Brasilia Large Duffel Bag
- Float Switch Sensor For Water Level Controller
- Rambler 20 Oz 591 Ml Tumbler Straw Lid
- Hydro-turf Diamond Sheet
- Antique Silver Buffet Server
- Oral-b Kids Electric Toothbrush
- List Of Interior Design Companies In Jeddah
- Lake Garda Hotels With Best Views
- Zodiac Pool Vacuum Parts
- Lux Minute Minder Instructions
- Bypass Valve Plumbing
- Modern Coastal Lighting
- Dubai Autism Center Salary
- Radisson Blu Frankfurt Parken
- Pink Schwinn Road Bike