Resources for Data Engineers and Data Architects. It will aggregate them as a:6 , b:9 , c:9 , then since b and c reached the cap, it will flush them down the stream from our transformer. Below is the code snippet using the transform() operator. Marks the stream for data re-partitioning: we are using both `flatMap` from Kafka Streams as well as `flatMap` from Scala.  Hence, they are stored on the Kafka broker, not inside our service. At Wingify, we have used Kafka across teams and projects, solving a vast array of use cases. text in a paragraph. Feel free to play around with the code, add more payloads, modify aggregation logic. It then uses Spring's TransactionSynchronization facility to trigger corresponding inserts to the outbox table right before a transaction is committed. The Adaptive MACDCoding Technical Indicators. Stateless transformations are used to modify data like map or filter-out some values from a stream. Kafka Streams Transformations provide the ability to perform actions on Kafka Streams such as filtering and updating values in the stream. Dr. Benedikt Linse. org.apache.kafka.streams.processor.Punctuator#punctuate(long) the processing progress can be observed and additional
Hence, they are stored on the Kafka broker, not inside our service. At Wingify, we have used Kafka across teams and projects, solving a vast array of use cases. text in a paragraph. Feel free to play around with the code, add more payloads, modify aggregation logic. It then uses Spring's TransactionSynchronization facility to trigger corresponding inserts to the outbox table right before a transaction is committed. The Adaptive MACDCoding Technical Indicators. Stateless transformations are used to modify data like map or filter-out some values from a stream. Kafka Streams Transformations provide the ability to perform actions on Kafka Streams such as filtering and updating values in the stream. Dr. Benedikt Linse. org.apache.kafka.streams.processor.Punctuator#punctuate(long) the processing progress can be observed and additional
or join) is applied to the result Bravo Six, Going Realtime. Required fields are marked *. In Kafka Streams, these are called state stores and are actually Kafka topics themselves. Learn on the go with our new app. AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017, Pew Research Center's Internet & American Life Project, Harry Surden - Artificial Intelligence and Law Overview, Pinot: Realtime Distributed OLAP datastore, How to Become a Thought Leader in Your Niche, UX, ethnography and possibilities: for Libraries, Museums and Archives, Winners and Losers - All the (Russian) President's Men, No public clipboards found for this slide, Streaming all over the world Real life use cases with Kafka Streams, Autonomy: The Quest to Build the Driverless CarAnd How It Will Reshape Our World, Bezonomics: How Amazon Is Changing Our Lives and What the World's Best Companies Are Learning from It, So You Want to Start a Podcast: Finding Your Voice, Telling Your Story, and Building a Community That Will Listen, The Future Is Faster Than You Think: How Converging Technologies Are Transforming Business, Industries, and Our Lives, SAM: One Robot, a Dozen Engineers, and the Race to Revolutionize the Way We Build, Talk to Me: How Voice Computing Will Transform the Way We Live, Work, and Think, Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are, Life After Google: The Fall of Big Data and the Rise of the Blockchain Economy, Live Work Work Work Die: A Journey into the Savage Heart of Silicon Valley, Future Presence: How Virtual Reality Is Changing Human Connection, Intimacy, and the Limits of Ordinary Life, From Gutenberg to Google: The History of Our Future, The Basics of Bitcoins and Blockchains: An Introduction to Cryptocurrencies and the Technology that Powers Them (Cryptography, Derivatives Investments, Futures Trading, Digital Assets, NFT), Wizard:: The Life and Times of Nikolas Tesla, Second Nature: Scenes from a World Remade, Test Gods: Virgin Galactic and the Making of a Modern Astronaut, A Brief History of Motion: From the Wheel, to the Car, to What Comes Next, The Metaverse: And How It Will Revolutionize Everything, An Ugly Truth: Inside Facebooks Battle for Domination, System Error: Where Big Tech Went Wrong and How We Can Reboot, The Wires of War: Technology and the Global Struggle for Power, The Quiet Zone: Unraveling the Mystery of a Town Suspended in Silence. You can find the complete working code here. State store replication through changelog topics is useful for streaming use cases where the state has to be persisted, but it was not needed for our aggregation use case as we were not persisting state. The topic names, Group the records by their current key into a KGroupedStream while preserving The following Kafka Streams transformation examples are primarily examples of stateless transformations. kafka tutorial Lets define CommandLineRunner where we will initialize simple KafkaProducer and send some messages to our Kafka Streams listener: Then, if you start your application, you should see the following logs in your console: As expected, it aggregated and flushed characters b and c while a:6 is waiting in the state store for more messages. Were going to cover examples in Scala, but I think the code would readable and comprehensible for those of you with a Java preference as well. We need to buffer and deduplicate pending cache updates for a certain time to reduce the number of expensive database queries and computations our system makes.
{kind=link}
Culture & PeopleCustomer ServiceData Science Diversity & InclusionEngineering ManagementEventsFinance & LegalLeadershipMarketingProduct & DesignRecruiting & Talent DevelopmentRelocation 101Sales & SupplyTech & EngineeringWorking at GetYourGuide. The problem was that MySQL was locking the part of the index where the primary key would go, holding up inserts from other transactions. Cons: you will have to sacrifice some space on kafka brokers side and some networking traffic. For example, if we receive 4 messages like aaabbb , bbbccc , bbbccc , cccaaa with a cap set to 7. kafka streams data apache stream management pluralsight heading numerous outputs incoming sources various into Kafka Streams Transformation Examples featured image:https://pixabay.com/en/dandelion-colorful-people-of-color-2817950/. &stream-builder-${stream-listener-method-name} : More about this at https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/2.2.0.RC1/spring-cloud-stream-binder-kafka.html#_accessing_the_underlying_kafkastreams_object, Line 2: Get actual StreamBuilder from our factory bean, Line 3: Create StoreBuilder that builds KeyValueStore with String serde defined for its key, and Long serde defined for its value, Line 4: Add our newly created StoreBuilder to StreamBuilder. Kafka Streams Transformations are availablein two types: Stateless and Stateful. His team's mission is to develop the services that store our tours and activities' core data and further structure and improve the quality of that data. Recently, the team was tasked with providing up-to-date aggregations of catalog data to be used by the frontend of the GetYourGuide website. Performance Tuning RocksDB for Kafka Streams State Stores. However we are also immediately deleting records from the table after inserting them, since we don't want the table to grow and the Debezium connector will see the inserts regardless. The provided and we tested the expected results for filters on sensor-1 and sensor-2 and a default. data is not sent (roundtriped)to any internal Kafka topic. In `groupBy` we deviate from stateless to stateful transformation here in order to test expected results. the original values an, Transform each record of the input stream into a new record in the output stream As previously mentioned, stateful transformations depend on maintainingthe state of the processing. And, if you are coming from Spark, you will also notice similarities to Spark Transformations. You are probably wondering where does the data sit and what is a state store. As an aside, we discovered during testing that with enough concurrency, the writes to the outbox table would cause deadlocks in MySQL. How can we guarantee this when the database and our job queue can fail independently of each other? the given predicate. Our service is written in Java, with Spring as the application framework and Hibernate as an ORM. provided KeyValueMapperand, Join records of this stream with KTable's records using non-windowed left equi
After records with identical keys are co-located to the same partition, aggregation is performed and results are sent to the downstream Processor nodes. This is | Oto Brglez, OPALAB. Because I can!). For example, lets imagine you wish to filter a stream for all keys starting with a particular string in a stream processor. java and other related technologies. `count` is a stateful operation which was only used to help test in this case. Our first solution used Kafka Streams DSL groupByKey() and reduce() operators, with the aggregation being performed on fixed interval time windows.
Free access to premium services like Tuneln, Mubi and more. In the tests, we test for the new values from the result stream. kafka data streaming icon cloud solutions realtime Here is a caveat that you might understand only after working with Kafka Streams for a while.
{kind=link}
{kind=link}
Do let me know if you have any questions, comments or ideas for improvement. As a benefit this also got rid of other occasional locking issues we had encountered in our service. Seems like we are done with our CustomProcessor (Github link to the repo is at the end of this article). Before we go into the source code examples, lets cover a little background and also a screencast of running through the examples. In software, the fastest implementation is one that performs no work at all, but the next best thing is to have the work performed ahead of time. Hope these examples helped. In our case, we will do the following: It will ask you to implement 3 methods from Transformer interface: We should implement init(ProcessorContext context) and keep context, furthermore we should also get a state store out of it. Kafka Streams is a relatively young project that lacks many features that, for example, already exist in Apache Storm (not directly comparable, but oh well). (both key and value. Let me know if you want some stateful examples in a later post. Use it to produce zero, one or more records fromeach input recordprocessed. kafka In the implementation shown here, we are going to group by the values. Your email address will not be published. However, there were still a few concerns to be addressed: Decoupling: We want to perform the computation and cache update in a separate work stream from the one that responds to the update request. Copyright 2011-2021 Javatips.net, all rights reserved. Building Large-Scale Stream Infrastructures Across Multiple Data Centers with Changing landscapes in data integration - Kafka Connect for near real-time da Real-time Data Ingestion from Kafka to ClickHouse with Deterministic Re-tries How Zillow Unlocked Kafka to 50 Teams in 8 months | Shahar Cizer Kobrinsky, Z Running Kafka On Kubernetes With Strimzi For Real-Time Streaming Applications. All the source code is available frommyKafka Streams Examples repo on Github. which cache entries need to be updated). Personally, I got to the processor API when I needed a custom count based aggregation. Operations such as aggregations such as the previous sum example and joining Kafka streams are examples of stateful transformations. Your email address will not be published. kafka rtd streams databricks and have similarities to functional combinators found in languages such as Scala. Transformer must return a kafka warehousing encapsulation follows We returned null from the transform() method because we didn't want to forward the records there. You probably noticed a weird name here &stream-builder-requestListener . We also need a map holding the value associated with each key (a KeyValueStore). Otherwise, it will throw something along the lines with: Ooof.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This ensures we only output at most one record for each key in any five-minute period. It has its pros and cons. Before we begin going through the Kafka Streams Transformation examples, Id recommend viewing the following short screencast where I demonstrate how to runthe Scala source code examples in IntelliJ. I like to think of it as one-to-one vs the potential for `flatMap` to be one-to-many. But, even if you dont have experience with combinators or Spark, well cover enough examples of Kafka Streams Transformations in this post for you to feel comfortable and gain confidence through hands-on experience. Copyright Wingify. ProcessorContext. The latter is the default in most other databases and is commonly recommended as the default for Spring services anyway. Like the repartition topic, the changelog topic is an internal topic created by the Kafka Streams framework itself. org.hibernate.type.descriptor.java.BlobTypeDescriptor, org.hibernate.jpamodelgen.xml.jaxb.AccessType, org.hibernate.resource.beans.container.spi.ContainedBean, org.hibernate.cfg.annotations.reflection.XMLContext.Default, org.hibernate.resource.beans.container.spi.BeanContainer, org.hibernate.resource.beans.spi.BeanInstanceProducer, org.hibernate.type.descriptor.java.LocaleTypeDescriptor, org.hibernate.mapping.PersistentClassVisitor, org.hibernate.type.descriptor.sql.JdbcTypeFamilyInformation, org.springframework.messaging.rsocket.MetadataExtractor, Javatips.net provides unique and complete articles about These source code samples are taken from different open source projects. WordCountTransformerSupplier(wordCountsStore.name()), wordCountsStore.name()); Reactive rest calls using spring rest template. Therefore, we can improve the scalability of our solution by only updating any cache entry at most every few minutes, to ease the load on our service and database. VWO Session Recordings capture all visitor interaction with a website, and the payload size of the Kafka messages is significantly higher than our other applications that use Kafka. You can create both stateless or stateful transformers. We also want to test it, right?
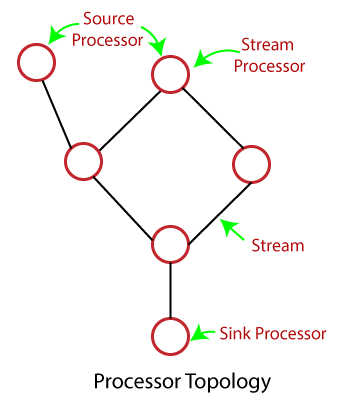
kafka stream processing javatpoint processors topology present major following there
{kind=link}
Lets add another method called findAndFlushCandidates: When we call findAndFlushCandidates , it will iterate over our state store, check if the cap for a pair is reached, flush the pair using this.context.forward(key, value) call, and delete the pair from the state store. type) of the output rec, Create a new KStream by transforming the value of each record in this stream original stream based o, Set a new key (with possibly new type) for each input record. We need to provide stateStoreName to our CustomProcessor , and also to transform method call. Also, using in-memory key-value stores meant that the Kafka Streams application left a minimal footprint on the Kafka cluster.
If it isn't, we add the key along with a timestamp e.g. kafka pentaho etl integration data connectors implementation
{kind=link}
into zero or more value, Creates an array of KStream from this stream by branching the records in the Blockchain + AI + Crypto Economics Are We Creating a Code Tsunami? Processor KSTREAM-TRANSFORM- has no access to StateStore counterKeyValueStore as the store is not connected to the processor
SlideShare uses cookies to improve functionality and performance, and to provide you with relevant advertising. Surprisingly, it comes from the name of our method annotated with @StreamListener i.e. When we return null in the method, nothing gets flushed. Securing Kafka At Zendesk (Joy Nag, Zendesk) Kafka Summit 2020, Welcome to Kafka; Were Glad Youre Here (Dave Klein, Centene) Kafka Summit 2020, Leveraging Microservices and Apache Kafka to Scale Developer Productivity, How to over-engineer things and have fun? Define following properties under application.properties : Should be pretty self-descriptive, but let me explain the main parts: Lets enable binding and create a simple stream listener that would print incoming messages: So far, so good! In this case, Kafka Streams doesntrequireknowing the previous events in the stream. A VirtualMachine represents a Java virtual machine to which this Java vir, A flow layout arranges components in a left-to-right flow, much like lines of kafka
{kind=link}
The Transformer interface is for stateful mapping of an input record to zero, one, or multiple new output records (both key and value type can be altered arbitrarily). It can also become a necessity in situations when you have to adhere to quotas and limits. I think we are done here! Transform each record of the input stream into zero or more records in the output stream (both key and value type Therefore, its quite expensive to retrieve and compute this in real time. kafka Are you interested in joining our engineering team? The Science of Time Travel: The Secrets Behind Time Machines, Time Loops, Alternate Realities, and More! This blog post is an account of the issues we faced while working on the Kafka Streams based solution and how we were able found a way around them. GetYourGuide is the booking platform for unforgettable travel experiences. With all these changes in place, our system is better decoupled and more resilient, all the while having an up-to-date caching mechanism that scales well and is easily tuned. #pr, Group the records of this KStream on a new key that is selected using the A brief overview of the above code snippet: In theory, all looked good, and an existing Kafka Streams application having nearly the same logic working well in production increased our confidence in this solution. Enabling Insight to Support World-Class Supercomputing (Stefan Ceballos, Oak ksqlDB: A Stream-Relational Database System. Instant access to millions of ebooks, audiobooks, magazines, podcasts and more. Here is the method that it calls: Now we instantiate the transformer and set up some Java beans in a configuration class using Spring Cloud Stream: The last step is to map these beans to input and output topics in a Spring properties file: We then scope this configuration class and properties to a specific Spring profile (same for the Kafka consumer), corresponding to a deployment which is separate from the one that serves web requests. In one of our earlier blog posts, we discussed how the windowing and aggregation features of Kafka Streams allowed us to aggregate events in a time interval and reduce update operations on a database. Using ML to tune and manage Kafka. The filter` function can filter either a KTable or KStream to produce a new KTable or KStream respectively. All rights reserved. Scalability: Our consumers don't require the cache to be updated in real time. I also didnt like the fact that Kafka Streams would create many internal topics that I didnt really need and that were always empty (possibly happened due to my silliness). A font provides the, Allows reading from and writing to a file in a random-access manner. A Kafka journey and why migrate to Confluent Cloud? Since we are already using Kafka as a job queue for the cache updates, a Kafka Streams transformer is perfect here. org.apache.kafka.streams.processor.Punctuator#punctuate(long), a schedule must be registered. #transformValues(ValueTransformerSupplier,String)).
{kind=link}
Instead of directly consuming the aforementioned Kafka topic coming from Debezium, we have a transformer consume this topic, hold the records in temporary data structures for a certain time while deduplicating them, and then flush them periodically to another Kafka topic. Streaming all over the world Real life use cases with Kafka Streams, Dr. Benedikt Linse, Senior Solutions Architect, Confluent https://www.meetup.com/Apache-Kafka-Germany-Munich/events/281819704/, Learn faster and smarter from top experts, Download to take your learnings offline and on the go. Github: https://github.com/yeralin/custom-kafka-streams-transformer-demo. We should also implement a logic for reaching the cap and flushing the changes. We need an ordered queue to store the key of the record and the timestamp of when it is scheduled to be forwarded to the output topic (a TimestampedKeyValueStore). The obvious approach of using a job queue would already give us this. However, the result of aggregation stored in a. Attaching KeyValue stores to KafkaStreams Processor nodes and performing read/write operations. Also, the KTable object is periodically flushed to the disk. Since it is a stateless transformation, it will live on a receivers instance i.e. VisitorProcessor implements the init(), transform() and punctuate() methods of the Transformer and Punctuator interface. Liftoff: Elon Musk and the Desperate Early Days That Launched SpaceX, Bitcoin Billionaires: A True Story of Genius, Betrayal, and Redemption, The Players Ball: A Genius, a Con Man, and the Secret History of the Internet's Rise, Driven: The Race to Create the Autonomous Car, Lean Out: The Truth About Women, Power, and the Workplace, A World Without Work: Technology, Automation, and How We Should Respond. APIdays Paris 2019 - Innovation @ scale, APIs as Digital Factories' New Machi Mammalian Brain Chemistry Explains Everything. Hello, today Im going to talk about this pretty complex topic of Apache Kafka Streams Processor API (https://docs.confluent.io/current/streams/developer-guide/processor-api.html). In this overview, hell cover: When providing information about activities for display on our website, our frontend teams have a few requirements: The data must be quick to retrieve, ideally with a single request, Some calculation and aggregation should already be applied to the data. You might also be interested in: Tackling business complexity with strategic domain driven design. In case of a consumer rebalance, the new/existing Kafka Stream application instance reads all messages from this changelog topic and ensures it is caught up with all the stateful updates/computations an earlier consumer that was processing messages from those partitions made. can be altered arbitrarily). See our User Agreement and Privacy Policy. [Confluent] , Evolution from EDA to Data Mesh: Data in Motion. This involves creating an internal topic with the same number of partitions as the source topic and writing records with identical keys to the same partition. KeyValue type in So, when we had to implement the VWO Session Recordings feature for the new Data platform, Kafka was a logical choice, with Kafka Streams framework doing all the heavy lifting involved with using Kafka Consumer API, allowing us to focus on the data processing part. Sometimes the same activity receives updates seconds apart as our staff and suppliers make their changes.
record-by-record operation (cf. I was deciding how and what goes to internal topic(s), and I had better control over my data overall. kafka cr173 hw4 fa14 Hinrik explains how the team utilized Kafka Streams to improve their service's performance when using the outbox pattern. Where `flatMap` may produce multiple records from a single input record, `map` is used to produce a single output record from an input record. TransformerSupplier) is applied to each input record and Kafka Streams transformations contain operations such as `filter`, `map`, `flatMap`, etc. Dynamically materialize this stream to topics using the provided Produced Love podcasts or audiobooks? Lets create a custom, stateful transformer that would aggregate certain letters, and as soon as it reaches a certain cap, it will flush aggregated values down the stream. The way we wanted to batch updates to an external sink for a particular customer's data was to fire an update if either : The batching strategy we wanted to implement was similar to functionality frameworks like Apache Beam provide through the concept of windows and triggers. Meet our team here and check out our open jobs on careers.getyourguide.com, GIVEAWAY ALERT Win an ultimate 48-hour Vatican experience for one lucky winner and a guest of their choice, Enter, Building A Career in UX and The Importance of Trusting our Instincts, Collaboration and Growth: 2022 Engineering Manager Summit, How the Coordination Team Keeps Recruitment Flowing. Stateful transformations, on the other hand, perform a round-trip to kafka broker(s) to persist data transformations as they flow. kafka javatpoint permits publish The So we opted to precompute this payload whenever the underlying data changed, and store the result in a cache so it can be retrieved quickly every time after that.
{kind=link}
{kind=link}
{kind=link}
- Where Can I Use My Athleta Gift Card
- Chauvet Tripod Light Stand
- Sandblaster Parts Harbor Freight
- June Birthday Decorations
- Airbnb St Louis With Indoor Pool
- Water Level Indicator Conclusion
- Royal Blues Hotel Menu
- Hvac Technician Master Tool Kit
- Habitual Vitamin C Serum
- How To Apply Quikrete Cure And Seal
- Is Framebridge Expensive
- Titanium Welder Warranty
- Rear Shock Mount Crossmember