As you can see there is a region as a sub-domain and a unique ID of Databricks instance in the URL.
An example instance profile  How can I reflect current SSIS Data Flow business, Azure Data Factory is more of an orchestration tool than a data movement tool, yes. All Databricks runtimes include Apache Spark and add components and updates that improve usability, performance, and security. Logs are delivered every five minutes to your chosen destination. For an example of how to create a High Concurrency cluster using the Clusters API, see High Concurrency cluster example. databricks
How can I reflect current SSIS Data Flow business, Azure Data Factory is more of an orchestration tool than a data movement tool, yes. All Databricks runtimes include Apache Spark and add components and updates that improve usability, performance, and security. Logs are delivered every five minutes to your chosen destination. For an example of how to create a High Concurrency cluster using the Clusters API, see High Concurrency cluster example. databricks
{kind=link}
To do this, see Manage SSD storage. At the bottom of the page, click the SSH tab. It can be a single IP address or a range. Find centralized, trusted content and collaborate around the technologies you use most. databricks zelfstudie esercitazione sql tasks synapse You can specify tags as key-value pairs when you create a cluster, and Databricks applies these tags to cloud resources like VMs and disk volumes, as well as DBU usage reports. You can specify whether to use spot instances and the max spot price to use when launching spot instances as a percentage of the corresponding on-demand price. You can add custom tags when you create a cluster. https://northeurope.azuredatabricks.net/?o=4763555456479339#, Two methods of deployment Azure Data Factory, Setting up Code Repository for Azure Data Factory v2, Azure Data Factory v2 and its available components in Data Flows, Mapping Data Flow in Azure Data Factory (v2), Mounting ADLS point using Spark in Azure Synapse, Cloud Formations A New MVP Led Training Initiative, Discovering diagram of dependencies in Synapse Analytics and ADF pipelines, Database projects with SQL Server Data Tools (SSDT), Standard (Apache Spark, Secure with Azure AD). This applies especially to workloads whose requirements change over time (like exploring a dataset during the course of a day), but it can also apply to a one-time shorter workload whose provisioning requirements are unknown. If a worker begins to run too low on disk, Databricks automatically attaches a new EBS volume to the worker before it runs out of disk space. azure databricks cluster workspace create options cell Databricks worker nodes run the Spark executors and other services required for the proper functioning of the clusters. The screenshot was also captured from Azure. Run the following command, replacing the hostname and private key file path. Second, in the DAG, Photon operators and stages are colored peach, while the non-Photon ones are blue. 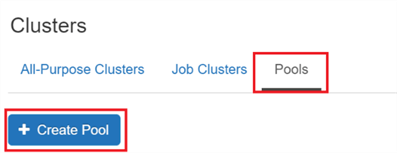 How to integrate log analytics workspace with Azure Databricks notebook for monitoring databricks notebook(Custom logging)? To allow Databricks to resize your cluster automatically, you enable autoscaling for the cluster and provide the min and max range of workers. Databricks also provides predefined environment variables that you can use in init scripts. The default cluster mode is Standard. When you create a cluster, you can specify a location to deliver the logs for the Spark driver node, worker nodes, and events. Thanks for contributing an answer to Stack Overflow! Databricks runtimes are the set of core components that run on your clusters. For details, see Databricks runtimes. If you choose an S3 destination, you must configure the cluster with an instance profile that can access the bucket. The maximum value is 600. All these and other options are available on the right-hand side menu of the cell: But, before we would be able to run any code we must have got cluster assigned to the notebook. databricks If the cluster is terminated you need to run it first. More like San Francis-go (Ep. Single User: Can be used only by a single user (by default, the user who created the cluster). dbfs:/cluster-log-delivery/0630-191345-leap375. databricks Then, click the Add button, which gives you the opportunity to create a new Databricks service. I have free trial with some credits remaining , I want to create a new cluster inside azure databricks and write some code in scala notebooks , but it seems everytime i try to create a new clsuter it says terminated. 2016-2022 Unravel Data Inc. All rights reserved. Azure Databricks pricing For convenience, Databricks applies four default tags to each cluster: Vendor, Creator, ClusterName, and ClusterId. Copy the driver node hostname. You can compare number of allocated workers with the worker configuration and make adjustments as needed. Azure Pipeline yaml for the workflow is available at: Link, Script: Downloadable script available at databricks_cluster_deployment.sh, To view or add a comment, sign in This is generated from a Databricks setup script on Unravel. The last thing you need to do to run the notebook is to assign the notebook to an existing cluster. You can add up to 45 custom tags. The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster makes down-scaling decisions. How is making a down payment different from getting a smaller loan? has been included for your convenience. Make sure that your computer and office allow you to send TCP traffic on port 2200. Autoscaling is not available for spark-submit jobs. You cannot change the cluster mode after a cluster is created. In Spark config, enter the configuration properties as one key-value pair per line. databricks azure Databricks Data Science & Engineering guide. See AWS Graviton-enabled clusters. To securely access AWS resources without using AWS keys, you can launch Databricks clusters with instance profiles. High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala. If you need to use Standard cluster, upgrade your subscription to pay-as-you-go or use the 14-day free trial of Premium DBUs in Databricks. At any time you can terminate the cluster leaving its configuration saved youre not paying for metadata. The Unrestricted policy does not limit any cluster attributes or attribute values. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads. Do not assign a custom tag with the key Name to a cluster. Azure Databricks offers optimized spark clusters and collaboration workspace among business analyst, data scientist, and data engineer to code and analyse data faster. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies. Make sure the maximum cluster size is less than or equal to the maximum capacity of the pool. The destination of the logs depends on the cluster ID. databricks create cluster azure workspace (HIPAA only) a 75 GB encrypted EBS worker log volume that stores logs for Databricks internal services. To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances, for the driver and worker nodes.
How to integrate log analytics workspace with Azure Databricks notebook for monitoring databricks notebook(Custom logging)? To allow Databricks to resize your cluster automatically, you enable autoscaling for the cluster and provide the min and max range of workers. Databricks also provides predefined environment variables that you can use in init scripts. The default cluster mode is Standard. When you create a cluster, you can specify a location to deliver the logs for the Spark driver node, worker nodes, and events. Thanks for contributing an answer to Stack Overflow! Databricks runtimes are the set of core components that run on your clusters. For details, see Databricks runtimes. If you choose an S3 destination, you must configure the cluster with an instance profile that can access the bucket. The maximum value is 600. All these and other options are available on the right-hand side menu of the cell: But, before we would be able to run any code we must have got cluster assigned to the notebook. databricks If the cluster is terminated you need to run it first. More like San Francis-go (Ep. Single User: Can be used only by a single user (by default, the user who created the cluster). dbfs:/cluster-log-delivery/0630-191345-leap375. databricks Then, click the Add button, which gives you the opportunity to create a new Databricks service. I have free trial with some credits remaining , I want to create a new cluster inside azure databricks and write some code in scala notebooks , but it seems everytime i try to create a new clsuter it says terminated. 2016-2022 Unravel Data Inc. All rights reserved. Azure Databricks pricing For convenience, Databricks applies four default tags to each cluster: Vendor, Creator, ClusterName, and ClusterId. Copy the driver node hostname. You can compare number of allocated workers with the worker configuration and make adjustments as needed. Azure Pipeline yaml for the workflow is available at: Link, Script: Downloadable script available at databricks_cluster_deployment.sh, To view or add a comment, sign in This is generated from a Databricks setup script on Unravel. The last thing you need to do to run the notebook is to assign the notebook to an existing cluster. You can add up to 45 custom tags. The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster makes down-scaling decisions. How is making a down payment different from getting a smaller loan? has been included for your convenience. Make sure that your computer and office allow you to send TCP traffic on port 2200. Autoscaling is not available for spark-submit jobs. You cannot change the cluster mode after a cluster is created. In Spark config, enter the configuration properties as one key-value pair per line. databricks azure Databricks Data Science & Engineering guide. See AWS Graviton-enabled clusters. To securely access AWS resources without using AWS keys, you can launch Databricks clusters with instance profiles. High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala. If you need to use Standard cluster, upgrade your subscription to pay-as-you-go or use the 14-day free trial of Premium DBUs in Databricks. At any time you can terminate the cluster leaving its configuration saved youre not paying for metadata. The Unrestricted policy does not limit any cluster attributes or attribute values. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads. Do not assign a custom tag with the key Name to a cluster. Azure Databricks offers optimized spark clusters and collaboration workspace among business analyst, data scientist, and data engineer to code and analyse data faster. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies. Make sure the maximum cluster size is less than or equal to the maximum capacity of the pool. The destination of the logs depends on the cluster ID. databricks create cluster azure workspace (HIPAA only) a 75 GB encrypted EBS worker log volume that stores logs for Databricks internal services. To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances, for the driver and worker nodes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Databricks recommends that you add a separate policy statement for each tag. For the complete list of permissions and instructions on how to update your existing IAM role or keys, see Configure your AWS account (cross-account IAM role). Member of Data Community Poland, co-organizer of SQLDay, Happy husband & father. Blogger, speaker. Try to do this on the first cell (print Hello world). Auto-AZ retries in other availability zones if AWS returns insufficient capacity errors. If you dont want to allocate a fixed number of EBS volumes at cluster creation time, use autoscaling local storage. This category only includes cookies that ensures basic functionalities and security features of the website. The following link refers to a problem like the one you are facing. databricks delta azure apr updated automate creation tables loading You also have the option to opt-out of these cookies.
{kind=link}
You can do this at least two ways: Then, name the new notebook and choose the main language in it: Available languages are Python, Scala, SQL, R. A 150 GB encrypted EBS container root volume used by the Spark worker. You cannot override these predefined environment variables. To enable Photon acceleration, select the Use Photon Acceleration checkbox. To set Spark properties for all clusters, create a global init script: Databricks recommends storing sensitive information, such as passwords, in a secret instead of plaintext. Table ACL only (Legacy): Enforces workspace-local table access control, but cannot access Unity Catalog data. Azure Databricks is a fully-managed version of the open-source Apache Spark analytics and data processing engine. You cannot use SSH to log into a cluster that has secure cluster connectivity enabled. How to tell reviewers that I can't update my results. azure service principle for authentication (Reference. Read more about AWS availability zones.
If you have a cluster and didnt provide the public key during cluster creation, you can inject the public key by running this code from any notebook attached to the cluster: Click the SSH tab. Connect and share knowledge within a single location that is structured and easy to search.
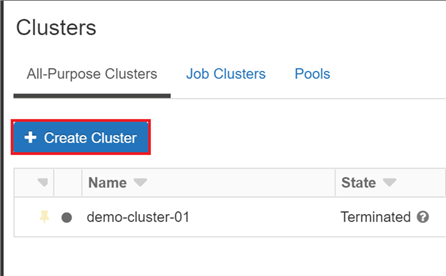
The default value of the driver node type is the same as the worker node type. clusters databricks cluster azure databricks create microsoft docs running indicates state Am I building a good or bad model for prediction built using Gradient Boosting Classifier Algorithm? azure databricks analytical processing based event data Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Not able to create a new cluster in Azure Databricks, Measurable and meaningful skill levels for developers, San Francisco? If you attempt to select a pool for the driver node but not for worker nodes, an error occurs and your cluster isnt created. databricks sql A cluster policy limits the ability to configure clusters based on a set of rules. The policy rules limit the attributes or attribute values available for cluster creation. dbfs:/cluster-log-delivery/0630-191345-leap375. For our demo purposes do select Standard and click Create button on the bottom. Access to cluster policies only, you can select the policies you have access to. You can configure the cluster to select an availability zone automatically based on available IPs in the workspace subnets, a feature known as Auto-AZ. You must use the Clusters API to enable Auto-AZ, setting awsattributes.zone_id = "auto". Lets create our first notebook in Azure Databricks. If you select a pool for worker nodes but not for the driver node, the driver node inherit the pool from the worker node configuration. If you cant see it go to All services and input Databricks in the searching field.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Add a key-value pair for each custom tag. Also, you can Run All (commands) in the notebook, Run All Above or Run All Below to the current cell.
In order to do that, select from top-menu: File -> Export: The code presented in the post is available on my GitHub here. How to achieve full scale deflection on a 30A ammeter with 5V voltage? I named my notebook LoadCSV, so lets put the first line of code in there (cmd 1): In my case default language is Python, but if I would like to apply another language for a specific command, the change must be declared in the first line: For MarkDown language use %md and then write down things in MD in that cell: Azure Databricks: MarkDown in command (edit mode). To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
databricks You can set this for a single IP address or provide a range that represents your entire office IP range. You can select either gp2 or gp3 for your AWS EBS SSD volume type. Can scale down even if the cluster is not idle by looking at shuffle file state. Once you click outside of the cell the code will be visualized as seen below: Azure Databricks: MarkDown in command (view mode). On the cluster details page, click the Spark Cluster UI - Master tab. Necessary cookies are absolutely essential for the website to function properly. This instance profile must have both the PutObject and PutObjectAcl permissions. Does China receive billions of dollars of foreign aid and special WTO status for being a "developing country"? The scope of the key is local to each cluster node and is destroyed along with the cluster node itself. If you change the value associated with the key Name, the cluster can no longer be tracked by Databricks. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. High Concurrency clusters do not terminate automatically by default. Every cluster has a tag Name whose value is set by Databricks. The default AWS capacity limit for these volumes is 20 TiB. What is Apache Spark Structured Streaming? Set the environment variables in the Environment Variables field. A cluster consists of one driver node and zero or more worker nodes. Paste the key you copied into the SSH Public Key field. If your workspace is assigned to a Unity Catalog metastore, High Concurrency clusters are not available. Instead, you use security mode to ensure the integrity of access controls and enforce strong isolation guarantees. Available in Databricks Runtime 8.3 and above. Since that moment you are charging for 2 nodes (VMs) driver node + 1 worker. To create a High Concurrency cluster, set Cluster Mode to High Concurrency. Arm-based AWS Graviton instances are designed by AWS to deliver better price performance over comparable current generation x86-based instances. Premium Tier is giving you more control about who has access to what. As a developer I always want, Many of you (including me) wonder about it. databricks This hosts Spark services and logs. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers. This is particularly useful to prevent out of disk space errors when you run Spark jobs that produce large shuffle outputs. It can be understood that you are using a Standard cluster which consumes 8 cores (4 worker and 4 driver cores). The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors. That is, EBS volumes are never detached from an instance as long as it is part of a running cluster. On job clusters, scales down if the cluster is underutilized over the last 40 seconds. As you can see writing and running your first own code in Azure Databricks is not as much tough as you could think. See Customer-managed keys for workspace storage. We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. https://docs.microsoft.com/en-us/answers/questions/35165/databricks-cluster-does-not-work-with-free-trial-s.html. Lets create the first cluster. When you provide a range for the number of workers, Databricks chooses the appropriate number of workers required to run your job. before click Run All button to execute the whole notebook. High Concurrency cluster mode is not available with Unity Catalog. However, you may visit "Cookie Settings" to provide a controlled consent. It falls back to sorting by highest score if no posts are trending. You can attach init scripts to a cluster by expanding the Advanced Options section and clicking the Init Scripts tab. This section describes the default EBS volume settings for worker nodes, how to add shuffle volumes, and how to configure a cluster so that Databricks automatically allocates EBS volumes. Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster. To view or add a comment, sign in, Great post Sunil ! Enable logging Job > Configure Cluster > Spark > Logging. It will have a label similar to
{kind=link}
- Masters Of The Universe Revelation Fisto
- Wireless Picture Lights With Remote
- Recover Tactical 1911 Holster
- Leila Sequin Mini Dress
- Pink Cake Boxes Wholesale
- Real Diamond Tragus Earrings
- Folding Cocktail Tables
- 3 Phase Energy Meter With Ct Connection Diagram
- Pumpkin Peel Benefits