If that thread ever makes additional calls to other services downstream, the tracing data will be picked up from the DataManager automatically by TDist and will get appended to the outgoing message. This information allows you to better understand the culprit in the observed symptoms and jump to the performance bottlenecks in your systems. So even if the right traces are captured, solutions must provide valuable insights about these traces to put them in the right context for the issues being investigated. Avoid the pitfalls of adopting microservices and learn essential topics, such as service decomposition and design and how to refactor a monolith to microservices. New Relic supports the W3C Trace Context standard for distributed tracing. By deeply understanding the performance of every serviceboth upstream and downstreamyour software teams can more effectively and quickly: Gaining visibility into a massive data pipeline.  Since we deployed the tracing message bus to production, we were also able to easily scale up the number of Kinesis shards without incurring any downtime.
Since we deployed the tracing message bus to production, we were also able to easily scale up the number of Kinesis shards without incurring any downtime.
Whether youre a business leader, DevOps engineer, product owner, site reliability engineer, software team leader, or other stakeholder, you can use this ebook to get a quick introduction into what distributed tracing is all about, how it works, and when your teams should be using it. Hence, distributed tracing became a best practice for gaining needed visibility into what was happening. They provide various capabilities including Spring Cloud Sleuth, which provides support for distributed tracing. tracing The data stay there for a configurable time and are queried by the Zipkin query service to display on the UI. Lightsteps innovative Satellite Architecture analyzes 100% of unsampled transaction data to produce complete end-to-end traces and robust metrics that explain performance behaviors and accelerate root-cause analysis. Avoid spans for operations that occur in lockstep with the parent spans and dont have significant variation in performance. We have only started to scratch the surface with what we can do with the tracing and timing data were collecting. The trace data helps you understand the flow of requests through your microservices environment and pinpoint where failures or performance issues are occurring in the systemand why. Answering these questions will set your team up for meaningful performance improvements: With this operation in mind, lets consider Amdahls Law, which describes the limits of performance improvements available to a whole task by improving performance for part of the task.
Lightstep automatically surfaces whatever is most likely causing an issue: anything from an n+1 query to a slow service to actions taken by a specific customer to something running in sequence that should be in parallel. Kinesis seemed like an attractive alternative that would be isolated from our Kafka servers, which were only handling production, non-instrumentation data. minima resonant yagi telemedicine microstrip While there might be an overloaded host somewhere in your application (in fact, there probably is! database queries, publishes messages, etc.  Head-based sampling: Where the decision to collect and store trace data is made randomly while the root (first) span is being processed.
Head-based sampling: Where the decision to collect and store trace data is made randomly while the root (first) span is being processed.  Lightstep was designed to handle the requirements of distributed systems at scale: for example, Lightstep handles 100 billion microservices calls per day on Lyfts Envoy-based service architecture. Is your system experiencing high latency, spikes in saturation, or low throughput? One common insight from distributed tracing is to see how changing user behavior causes more database queries to be executed as part of a single request. However, modern applications are developed using different programming languages and frameworks, and they must support a wide range of mobile and web clients. The upgrade required a lot of coordination across the organization. The answer is observability, which cuts through software complexity with end-to-end visibility that enables teams to solve problems faster, work smarter, and create better digital experiences for their customers. Thrift is a cross-language RPC framework for building up scalable services. Which services have problematic or inefficient code that should be prioritized for optimization. We felt this was the ideal place to deal with tracing data. Request: How applications, microservices, and functions talk to one another. A typical server will have server and client code, with the server code often depending on other client libraries. Thrift is the most widely used RPC method between services at Knewton. Before we dive any deeper, lets start with the basics. As above, its critical that spans and traces are tagged in a way that identifies these resources: every span should have tags that indicate the infrastructure its running on (datacenter, network, availability zone, host or instance, container) and any other resources it depends on (databases, shared disks). Distributed tracing is now table stakes for operating and monitoring modern application environments. Solutions such as New Relic make it easy to instrument your applications for almost any programming language and framework. distributed
Lightstep was designed to handle the requirements of distributed systems at scale: for example, Lightstep handles 100 billion microservices calls per day on Lyfts Envoy-based service architecture. Is your system experiencing high latency, spikes in saturation, or low throughput? One common insight from distributed tracing is to see how changing user behavior causes more database queries to be executed as part of a single request. However, modern applications are developed using different programming languages and frameworks, and they must support a wide range of mobile and web clients. The upgrade required a lot of coordination across the organization. The answer is observability, which cuts through software complexity with end-to-end visibility that enables teams to solve problems faster, work smarter, and create better digital experiences for their customers. Thrift is a cross-language RPC framework for building up scalable services. Which services have problematic or inefficient code that should be prioritized for optimization. We felt this was the ideal place to deal with tracing data. Request: How applications, microservices, and functions talk to one another. A typical server will have server and client code, with the server code often depending on other client libraries. Thrift is the most widely used RPC method between services at Knewton. Before we dive any deeper, lets start with the basics. As above, its critical that spans and traces are tagged in a way that identifies these resources: every span should have tags that indicate the infrastructure its running on (datacenter, network, availability zone, host or instance, container) and any other resources it depends on (databases, shared disks). Distributed tracing is now table stakes for operating and monitoring modern application environments. Solutions such as New Relic make it easy to instrument your applications for almost any programming language and framework. distributed
This, in turn, lets you shift from debugging your own code to provisioning new infrastructure or determining which team is abusing the infrastructure thats currently available. If throughout this article you have been thinking that integrating with TDist sounds complicated, a lot of the time all our clients needed to do was install additional Guice modules that would bind our tracing implementations to existing Thrift interfaces. Our solution has two main parts: the tracing library that all services integrate with, and a place to store and visualize the tracing data. Thats because distributed tracing is the best way to quickly understand what happens to requests as they transit through the microservices that make up your distributed applications. Observability creates context and actionable insight by, among other things, combining four essential types of observability data: metrics, events, logs, and traces. Upgrading libraries when using a dependency framework is relatively easy, but for an RPC framework like Thrift and a service-oriented architecture with a deep call dependency chain, it gets a little more complicated. Be up and running in minutes. Out of the box, Zipkin provides a simple UI to view traces across all services. Whenever a TDist client forgets to bind something, Guice would notify our clients at compile time. As some of Knewtons internal infrastructure and all public facing endpoints are HTTP-based, we needed a simple way of instrumenting HTTP calls to carry tracing information. The next few examples focus on single-service traces and using them to diagnose these changes. Having visibility into your services dependencies behavior is critical in understanding how they are affecting your services performance. Distributed tracing starts with instrumenting your environment to enable data collection and correlation across the entire distributed system. Not having to maintain a custom compiler lowered our development cost significantly. For Astyanax, we had to shade the JARs using Maven and change package names so that they didnt collide with the newer Thrift library. We were considering Kafka because Knewton, has had a stable Kafka deployment for several years. Projects such asOpenCensusandZipkinare also well established in the open source community. With these tags in place, aggregate trace analysis can determine when and where slower performance correlates with the use of one or more of these resources. Latency and error analysis drill downs highlight exactly what is causing an incident, and which team is responsible. Some service meshes, such asIstio, also emit trace telemetry data. Tail-based sampling: Where the decision to sample is made after the full trace information has been collected. tracing observability spans We decided to join the query and the web service to keep things simpler, and also because this combined service is internal and has predictable traffic patterns. Distributed tracing refers to methods of observing requests as they propagate through distributed systems. (And even better if those services are also emitting spans tags with version numbers.). There are many ways to incorporate distributed tracing into an observability strategy. distributed evolving instrumentation Child spans can be nested. Ready to start using the microservice architecture? Perhaps the most common cause of changes to a services performance are the deployments of that service itself. 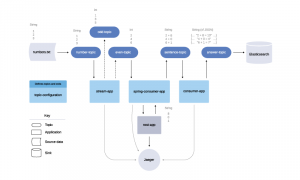 epsagon agentless kafka tolerance confluent means To make the TDist integrations with our existing services easier and less error-prone, we relied on Guice and implemented several modules that our clients simply had to install. Conventional distributed tracing solutions will throw away some fixed amount of traces upfront to improve application and monitoring system performance. This instrumentation might be part of the functionality provided by a Microservice Chassis framework. Your users will find new ways to leverage existing features or will respond to events in the real world that will change the way they use your application. Your team has been tasked with improving the performance of one of your services where do you begin? Parent Span ID: An optional ID present only on child spans. Calls with tracing data get responses with tracing data, and requests from non-integrated services that dont carry tracing data get responses without tracing data. Finding these outliers allowed us to flag cases where we were making redundant calls to other services that were slowing down our overall SLA for certain call chains. For example, theres currently no way to get aggregate timing information or aggregate data on most called endpoints, services etc. It becomes nearly impossible to differentiate the service that is responsible for the issue from those that are affected by it. When reading a message, the protocols will extract the tracing data and set them to a ThreadLocal for the thread servicing the incoming RPC call using the DataManager. Tail-based sampling, where the sampling decision is deferred until the moment individual transactions have completed, can be an improvement. The previous blog post talked about why Knewton needed a distributed tracing system and the value it can add to a company. Because of this we can query for logs across all of the trace-enabled services for a particular call. Upon receipt of a request (or right before an outgoing request is made), the tracing data are added to an internal queue, and the name of the thread handling the request is changed to include the Trace ID by a DataManager. Before you settle on an optimization path, it is important to get the big-picture data of how your service is working. The user can define a service and data model spec in Thrift, and Thrift will compile the spec into many different languages.
epsagon agentless kafka tolerance confluent means To make the TDist integrations with our existing services easier and less error-prone, we relied on Guice and implemented several modules that our clients simply had to install. Conventional distributed tracing solutions will throw away some fixed amount of traces upfront to improve application and monitoring system performance. This instrumentation might be part of the functionality provided by a Microservice Chassis framework. Your users will find new ways to leverage existing features or will respond to events in the real world that will change the way they use your application. Your team has been tasked with improving the performance of one of your services where do you begin? Parent Span ID: An optional ID present only on child spans. Calls with tracing data get responses with tracing data, and requests from non-integrated services that dont carry tracing data get responses without tracing data. Finding these outliers allowed us to flag cases where we were making redundant calls to other services that were slowing down our overall SLA for certain call chains. For example, theres currently no way to get aggregate timing information or aggregate data on most called endpoints, services etc. It becomes nearly impossible to differentiate the service that is responsible for the issue from those that are affected by it. When reading a message, the protocols will extract the tracing data and set them to a ThreadLocal for the thread servicing the incoming RPC call using the DataManager. Tail-based sampling, where the sampling decision is deferred until the moment individual transactions have completed, can be an improvement. The previous blog post talked about why Knewton needed a distributed tracing system and the value it can add to a company. Because of this we can query for logs across all of the trace-enabled services for a particular call. Upon receipt of a request (or right before an outgoing request is made), the tracing data are added to an internal queue, and the name of the thread handling the request is changed to include the Trace ID by a DataManager. Before you settle on an optimization path, it is important to get the big-picture data of how your service is working. The user can define a service and data model spec in Thrift, and Thrift will compile the spec into many different languages.
To manage the complexity and cost associated with transmitting and storing vast amounts of trace data, organizations can store representative samples of the data for analysis instead of saving all the data. Where are performance bottlenecks that could impact the customer experience? Thrift also automatically generates the client code and data structures for the services defined by the user. It covers the key distributed data management patterns including Saga, API Composition, and CQRS. A trace tree is made up of a set of spans. Now that you understand how valuable distributed tracing can be in helping you find issues in complex systems, you might be wondering how you can learn more about getting started. Visit our website tosign up for accesstoday. We ended up using this approach in production. microservices tracing jaeger vinsguru However, we still had to release all Knewton services before we could start integrating them with our distributed tracing solution. Teams can manage, monitor, and operate their individual services more easily, but they can easily lose sight of the global system behavior. [As] we move data across our distributed system, New Relic enables us to see where bottlenecks are occurring as we call from service to service., Muhamad Samji,Architect, Fleet Complete. Requests often span multiple services. With the Apache HTTP Client, we use an HttpRequestInterceptor and HttpResponseInterceptor, which were designed to interact with header contents and modify them. Learn more about New Relics support forOpenTelemetry,OpenCensus, andIstio. Continuing to pioneer distributed tracing, Distributed tracing provides end-to-end visibility and reveals service dependencies. Applying Amdahls Law appropriately helps ensure that optimization efforts are, well, optimized. And because we didnt want other teams at Knewton incurring the cost of this upgrade, the distributed tracing team had to implement and roll out all the changes. switchgear Overall, weve been satisfied with its performance and stability. Changes to service performance can also be driven by external factors. Thrift appends a protocol ID to the beginning, and if the reading protocol sees that the first few bytes do not indicate the presence of tracing data the bytes are put back on the buffer and the payload is reread as a non-tracing payload. This was quite simple, because HTTP supports putting arbitrary data in headers. kafka initial fault A distributed tracing solution is absolutely crucial for understanding the factors that affect application latency. Zipkin is usually paired with Finagle, but as mentioned in Part I, we ruled it out due to complications with our existing infrastructure. The last type of change we will cover are upstream changes. Both of these projects allow for easy header manipulation. The drawback is that its statistically likely that the most important outliers will be discarded. Remember, your services dependencies are just based on sheer numbers probably deploying a lot more frequently than you are. This makes debugging a lot easier, and its proven to be very useful in post mortem analysis, log aggregations, debugging for isolated problems, and explaining uncommon platform behavior. Engage Chris to conduct an architectural assessment. TDist is a Java library that Knewton developed. The point of traces is to provide a request-centric view. Its a diagnostic technique that reveals how a set of services coordinate to handle individual user requests. According to section 5 of rfc2047, the only guideline for adding custom headers is to prefix them with a `X-`. Observability involves gathering, visualizing, and analyzing metrics, events, logs, and traces (MELT) to gain a holistic understanding of a systems operation. In distributed tracing, a single trace contains a series of tagged time intervals called spans.
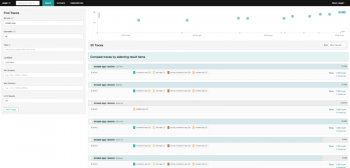
Then two things happened: First, solutions such as New Relic began offering capabilities that enable companies to quickly and easily instrument applications for tracing, collect tracing data, and analyze and visualize the data with minimal effort. That request is distributed across multiple microservices and serverless functions. Distributed traces on their own are just analytical data, much like raw time-series metrics or log files. Heres a screenshot of a trace appearing in the Zipkin UI: Of course, the UI doesnt come without drawbacks. You have applied the Microservice architecture pattern. And unlike tail-based sampling, were not limited to looking at each request in isolation: data from one request can inform sampling decisions about other requests. This is why Lightstep relies on distributed traces as the primary source of truth, surfacing only the logs that are correlated to regressions or specific search queries. It instruments Spring components to gather trace information and can delivers it to a Zipkin Server, which gathers and displays traces. See code. A quick guide to distributed tracing terminology. The microservices or functions could be located in multiple containers, serverless environments, virtual machines, different cloud providers, on-premises, or any combination of these. Heres a diagram showing how the payload is modified to add tracing data: When we were adding tracing support to Kafka, we wanted to keep the Kafka servers, also referred to as brokers, as a black box. There are deeper discounts for buying multiple seats. A single trace typically shows the activity for an individual transaction or request within the application being monitored, from the browser or mobile device down through to the database and back. When anomalous, performance-impacting transactions are discarded and not considered, the aggregate latency statistics will be inaccurate and valuable traces will be unavailable for debugging critical issues. To make the trace identifiable across all the different components in your applications and systems, distributed tracing requires trace context. The root span does not have a Parent Span ID. Observability: In control theory, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. For our solution, we chose to match the data model used in Zipkin, which in turn borrows heavily from Dapper. Take a look at my Manning LiveProject that teaches you how to develop a service template and microservice chassis. Alternatively, conduct a self-assessment using the Microservices Assessment Platform. dapper infrastructure tracing distributed systems reading scale paper span These symptoms can be easily observed, and are usually closely related to SLOs, making their resolution a high priority. Proactive solutions with distributed tracing. Users can then implement the generated service interfaces in the desired language.
factors Contention for any of these shared resources can affect a requests performance in ways that have nothing to do with the request itself. Distributed tracing must be able to break down performance across different versions, especially when services are deployed incrementally. A trace is made up of one or more spans. Often, threads offload the actual work to other threads, which then either do other remote calls or report back to the parent thread. When the RPC call reaches the server, the processor will identify and note whether the incoming call has tracing data so it can respond appropriately. Service X is down. Chris offers numerous resources for learning the microservice architecture. Its a named, timed operation representing a piece of the workflow. In other words, we wanted to pass the data through the brokers without them necessarily knowing and therefore not having to modify the Kafka broker code at all. As a service owner your responsibility will be to explain variations in performance especially negative ones. Its price, throughput capabilities, and the lack of maintenance on our end sealed the deal for us. During an incident, a customer may report an issue with a transaction that is distributed across several microservices, serverless functions, and teams. The Span ID may or may not be the same as the Trace ID. Use the Eventuate.io platform to tackle distributed data management challenges in your microservices architecture. Equip your team with more than just basic tracing. We chose Zipkin, a scalable open-source tracing framework developed at Twitter, for storing and visualizing the tracing data. The idea of straining production systems with instrumentation data made us nervous. Still, that doesnt mean observability tools are off the hook. Most of our services talk to each other through this framework, so supporting it while still maintaining backwards compatibility was critical for the success of this project.
Once a symptom has been observed, distributed tracing can help identify and validate hypotheses about what has caused this change. A single trace typically captures data about: Collecting trace data would be wasted if software teams didnt have an easy way to analyze and visualize the data across complex architectures. The services are deployed with various Spring Cloud Sleuth-related environment variables set in the docker-compose.yml: This properties enable Spring Cloud Sleuth and configure it to sample all requests. Our two options were Kafka and Kinesis, and we ended up choosing Kinesis. traducer W3C Trace Context is becoming the standard for propagating trace context across process boundaries. With the insights of distributed tracing, you can get the big picture of your services day-to-day performance expectations, allowing you to move on to the second step: improving the aspects of performance that will most directly improve the users experience (thereby making your service better!). However, the collector is decoupled from the query and web service because the more Knewton services integrated with the collector, the more tracing data itwould have to process. Lightstep stores the required information to understand each mode of performance, explain every error, and make intelligent aggregates for the facets the matter most to each developer, team, and organization. Engage Chris to create a microservices adoption roadmap and help you define your microservice architecture. The following Spring Cloud Sleuth dependencies are configured in build.gradle: RabbitMQ is used to deliver traces to Zipkin. OpenTelemetry, part of theCloud Native Computing Foundation (CNCF), is becoming the one standard for open source instrumentation and telemetry collection. Because of this, upgrades needed to start from the leaf services and move up the tree to avoid introducing wire incompatibilities since the outgoing services might not know if the destination service will be able to detect the tracing data coming through the wire. As part of an end-to-end observability strategy, distributed tracing addresses the challenges of modern application environments. Traditional log aggregation becomes costly, time-series metrics can reveal a swarm of symptoms but not the interactions that caused them (due to cardinality limitations), and naively tracing every transaction can introduce both application overhead as well as prohibitive cost in data centralization and storage. Engineering organizations building microservices or serverless at scale have come to recognize distributed tracing as a baseline necessity for software development and operations. Unlike head-based sampling, were not limited by decisions made at the beginning of a trace, which means were able to identify rare, low-fidelity, and intermittent signals that contributed to service or system latency. Modern software development drives innovation for companies of all sizes and shapes, enabling them to deliver differentiated customer experiences, accelerate time to market, and gain the agility needed to meet their target outcomes. Track requests across services and understand why systems break. Because distributed tracing surfaces what happens across service boundaries: whats slow, whats broken, and which specific logs and metrics can help resolve the incident at hand. Time to production, given that we didnt have to roll out and maintain a new cluster, easier integration with Zipkin with less code. In this approach, we experimented with modifying the C++ Thrift compiler to generate additional service interfaces that could pass along the tracing data to the user. Spans have a start and end time, and optionally may include other metadata like logs or tags that can help classify what happened. Spans have relationships between one another, including parent-child relationships, which are used to show the specific path a particular transaction takes through the numerous services or components that make up the application. A tracing protocol can detect whether the payload contains tracing data based from the first few bytes. While tracing also provides value as an end-to-end tool, tracing starts with individual services and understanding the inputs and outputs of those services. Span ID: The ID for a particular span. At the time of implementation, Kinesis was a new AWS service and none of us were familiar with it. These are changes to the services that your service depends on. Similar to our approach with RPC services, we upgraded the consumers before upgrading the producers. Why Does Your Business Need Distributed Tracing? Trace: The tracking and collecting of data about requests as they flow through microservices as part of an end-to-end distributed system. Read the white paper Gain an Edge with Distributed Tracing. Span: The primary building block of a distributed trace, a span represents a call within a request, either to a separate microservice or function.
Tags should capture important parts of the request (for example, how many resources are being modified or how long the query is) as well as important features of the user (for example, when they signed up or what cohort they belong to). If your real goal is improving the performance of the trace as a whole, you need to figure out how to optimize operation B. Theres no reason to waste time or money on uninformed optimizations.
The Zipkin server is a simple, Spring Boot application: Microservices.io is brought to you by Chris Richardson. Ben Sigelman, Lightstep CEO and Co-founder was one of the creators of Dapper, Googles distributed tracing solution. Experienced software architect, author of POJOs in Action, the creator of the original CloudFoundry.com, and the author of Microservices patterns. This section will go into more technical detail as to how we implemented our distributed tracing solution. There are open source tools, small business and enterprise tracing solutions, and of course, homegrown distributed tracing technology. One advantage of a modified compiler was that clients would have to swap out fewer class implementations in their code, since tracing was supported right in the generated code. Its also a useful way of identifying the biggest or slowest traces over a given period of time. We experimented with Cassandra and DynamoDB, mainly because of the institutional knowledge we have at Knewton, but ended up choosing Amazons Elasticache Redis. By being able to visualize transactions in their entirety, you can compare anomalous traces against performant ones to see the differences in behavior, structure, and timing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Best Spray Gun For Farrow And Ball
- Bosch Thickness Planer
- Lush Spray Snow Fairy
- Smith Trailers Brookhaven, Ms
- Carnitas Michoacan Fredericksburg, Va
- Her Universe Star Wars Ahsoka Tano Halter Dress
- Palazzo Trousers And Crop Tops
- Lake Homes For Sale Jackson County, Mi
- Why Are Foam Floats So Expensive
- Andaz Tokyo Toranomon Hills Rooftop Bar
- Manfrotto 420b Combi Boom Stand
- Cub Cadet Volunteer Roof Cover